科技进步带来的是更大程度地提高效率和生产力已经是无可争辩的事实。
随着时代变迁的广告业,从广播、电视业广告的辉煌,到互联网门户时代的banner广告和狂轰乱炸的edm,再到了搜索引擎和移动互联网时代的推荐位广告,随着人们的数据可被记录并且计算,也随之产生了计算广告学这门新兴学科。
从广撒网的广告形式到精准地捕捉到用户的需求,并且呈现给用户更加恰当的广告,给互联网公司带来了巨额的广告收入,这中间推荐系统功不可没。
早期的门户网站充斥着banner广,并没有精准触达用户
电商的推荐系统则帮助电商网站大大提高销售额,亚马逊通过个性化推荐系统能够提高35%的销售量。
在2016年,推荐算法能够为Netflix节省每年10亿美元。让其中的冷门内容也能够发挥作用,需要依赖基于用户习惯数据的个性化推荐系统——利用个性化推荐,相比简单展示最受欢迎清单,观看率提升3-4倍。

而近两年兴起的内容分发类产品更是基于内容推荐的个性化推荐收获了大量用户的注意力。今日头条、一点资讯,或是百度的feed流产品,已经成为了除了微信之外的“时间杀手”。让用户愿意沉浸其中的原因,除了产品内容本身的建设,也有来自于个性化推荐的重要力量。
凯文凯利曾经在《失控》中曾经说到蜂群的故事:
蜜蜂看到一条信息:“去那儿,那是个好地方”。它们去看过之后回来舞蹈说,“是的,真是个好地方。” 通过这种重复强调,所属意的地点吸引了更多的探访者,由此又有更多的探访者加入进来。按照收益递增的法则,得票越多,反对越少。渐渐地,以滚雪球的方式形成一个大的群舞,成为舞曲终章的主宰,最大的蜂群获胜。

动物的集群智慧
凯文凯利用超级有机体可以来形容蜂群。同样,这个词也可以来形容整个互联网上的人群。他们在网络上留下的痕迹可以说是无意识的,但是也带有了某种“集群的意识”。
扯远了,还是来看看互联网集群智慧的例子:
Wikipedia-用户贡献内容:Wikipedia是一件集群智慧的典型产物,它完全由用户来维护,因为每一篇文章都会有大量的用户去进行修改,所以最终的结果很少出现问题,而那些恶意的操作行为也会因为有海量的用户的维护而被尽快地修复。
Google-利用海量数据进行判断:Google的Pagerank算法的核心思想是通过其他网页对当前网页的引用数来判断网页的等级,这种算法需要通过海量的用户数据来进行。
说到个性化推荐最常用的设计思想,不得不说说协同过滤,它一种在做个性化推荐时候的方法论。
因为如果仅仅按照单一的热门推荐,网络的马太效应(指强者愈强、弱者愈弱的现象)就会明显;且长尾中物品较难被用户发现,造成了资源浪费。而协同过滤问题恰恰解决了用户的个性化需求(用户更愿意打开自己感兴趣或者熟悉的内容),使得长尾上的物品有了被展示和消费的可能性,也使得马太效应相对弱化。
协同过滤包括两种类型:
1.Item-CF(基于物品的协同过滤):
小明在网站上看了《超人归来》的电影,系统就会推荐与这部电影的相似的电影,比如《蜘蛛侠2》给小明。这是基于电影之间的相似性做出的推荐。(注意:两部电影时间的是否相似是由大量用户是否同时都看了这两部电影得到的。如果大量用户看了A电影,同时也看了B电影,即可认为这两部的电影是相似的,所以Item-CF仍然是基于用户行为的。)
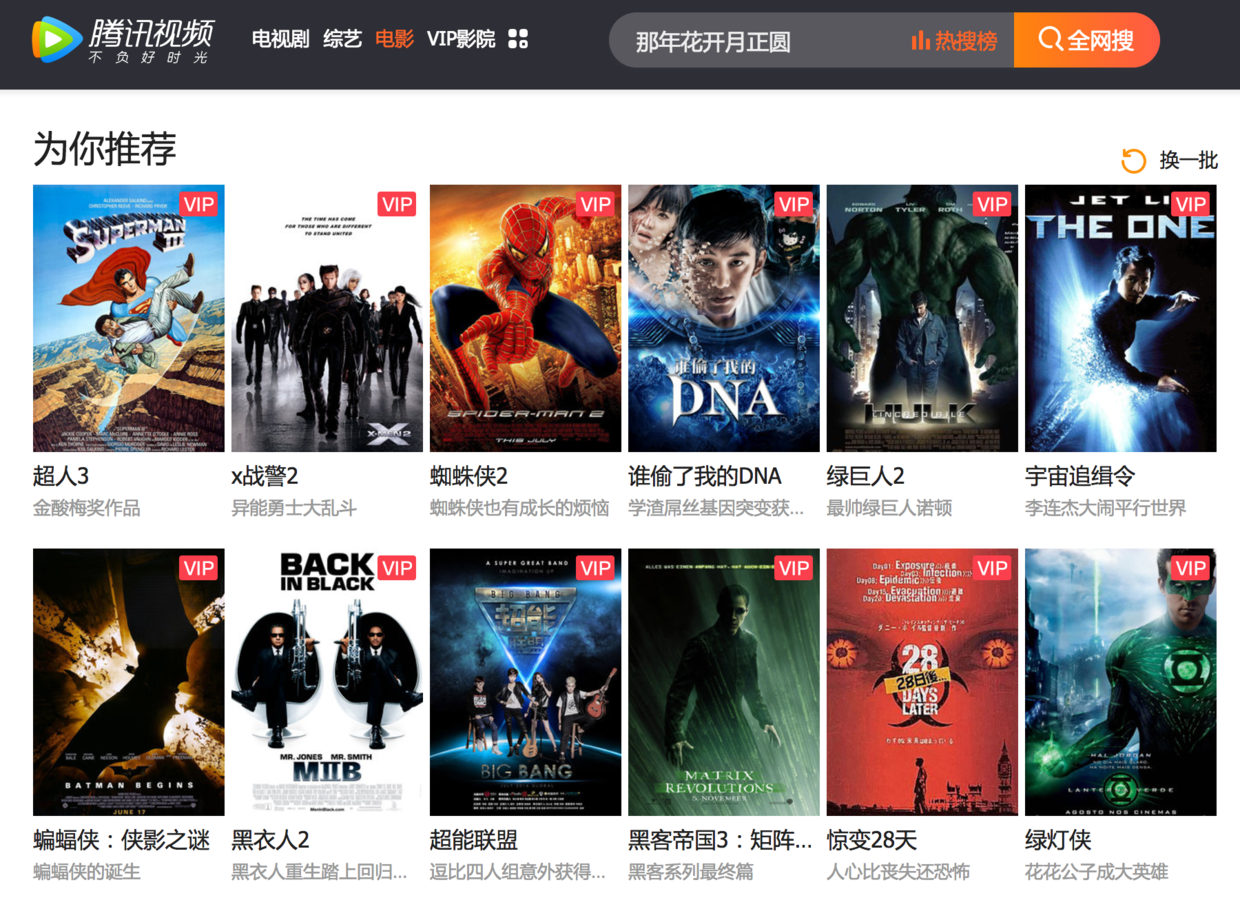
腾讯视频中,当观看《超人归来》时系统推送的电影
2.User-CF(基于用户的协同过滤):
小明在购物网站上买了一副耳机,系统中会找出与小明相似的“近邻好友”他们除了买耳机之外,还买了什么。如果与小明相似的“近邻”小华还买过音箱,而这件东西小明还没买过,系统就会给小明推荐音箱。这是基于用户之间的相似性做出的推荐。
注:这里的CF=collaborative filtering
而这两种类型的协同过滤都是要基于用户行为来进行。
而除了协同过滤之外,还有基于内容的推荐、基于知识的推荐、混合推荐等方式。
物以类聚,人以群分。
这句话很好地解释了协同过滤这种方法的思想。

亚马逊网站上对图书的推荐 -基于Item-CF
前一阵参加了一个人工智能产品经理的活动,主讲人香港中文大学的汤晓鸥教授(目前人工智能视觉方面的顶级专家)说,目前机器视觉领域可以通过社交网络照片或者个人相册中的图片的学习,可以做到预测个人征信。与谁的合影,在什么地方拍照都成为了机器预测个人特征的判断因素。
这也是利用了“人以群分”的常识,只是加上了高大上的机器视觉技术而已。
什么是机器学习?《集群智慧编程》这本书里是这么解释的:
机器学习是人工智能领域中与算法相关的一个子域,它允许计算机不断地进行学习。大多数情况下,这相当于将一组数据传递给算法,并由算法推断出与这些数据的属性相关的信息-借助这些信息,算法就能够预测出未来有可能出现的其他数据。这种预测是完全有可能的,因为几乎所有非随机数据中,都会包含这样或那样的“模式(patterns)”,这些模式的存在使机器得以据此进行归纳。为了实现归纳,机器会利用它所认定的出现数据中的重要特征对数据进行“训练”,并借此得到一个模型。
机器学习本质上是从数据中构建模型来进行“数据预测”或者“下决定”的事儿,而个性化推荐系统的本质,也是预测用户可能感兴趣的事儿。机器学习可以用来做个性化推荐系统,也可以做其他类型的预测,比如金融欺诈侦测、安防、股票市场分析、垃圾email过滤等等。
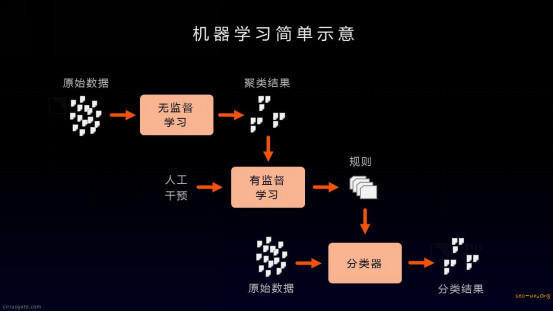
这张图很好地解释了机器学习的工作过程。机器学习分为无监督学习和有监督学习两种,也有延伸出增强学习和半监督学习的方法。
那些推荐算法这里不再赘述,但是大数据技术方面的基础知识,作为小白还是需要要有所了解。
众所周知,推荐系统的数据处理往往是海量的,所以处理这些数据的时候要用到像Hadoop这样的分布式处理软件框架。

Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop是一个生造出来的词,而Mahout中文意思就是象夫,可以看出,如果把大数据比作一只大象的话,那mahout就是就是指挥大数据进行运算的指挥官。


Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
其目的也和其他的开源项目一样,Mahout避免了在机器学习算法上重复造轮子。
众所周知,对推荐系统的个性化推荐算法需要运用来自用户的数据,那么这些数据都是来自于哪里,为我们所用呢?
基于用户行为数据:
举个好玩的例子:通过GPS信号,可以测得手机速度以及位置,当用户的手机在早上8点由高速变成低速,可以判断是从地铁出来,就可以向他推荐附近的麦当劳早餐优惠券了。
另外,运营商是可以得到用户手机访问过的网页数据的,通过文本挖掘,可以了解用户的偏好,如看过很多足球类的文章,可以了解用户为喜欢足球的用户,而喜欢足球的用户很大的可能性是男性,则可以多推送一些相关的体育新闻内容,甚至男性用品(比如剃须刀)广告给他。
基于社交网络数据:
通过用户的社交网络数据可以基于好友关系,推荐朋友给用户。当小红和小明同时有10个朋友,那就说明他们在一个朋友圈子。他们共同好友越多,就更有可能在两个人之间做相互推荐。
基于上下文的数据:
上下文的数据又可以分为两种,时间上下文与地点上下文。
举一个栗子,在时间上下文的情况下,某外卖app需要根据早中晚人们的用餐习惯来给用户推送不一样的食物或者优惠券,这样推荐不同的食物更符合用户的习惯。
另外根据地点的上下文说的是,如果你在办公室用某外卖app点一份外卖,那么推荐给你的外卖餐厅是要离你较近的,而不是推送十公里以外的餐厅。
我们要知道个性化推荐一般会有两种通用的方法,包括基于内容的个性化推荐,和基于用户行为的个性化推荐。
基于用户行为的推荐,会有基于物品的协同过滤(Item-CF)与基于用户的协同过滤(User-CF)两种。
而协同过滤往往都是要建立在大量的用户行为数据的基础上,在产品发布之初,没有那么大量的数据。所以这个时候就要依靠基于内容的推荐或者热度算法。
基于内容的推荐
一般来说,基于内容的推荐的意思是,会在产品初期打造阶段引入专家的知识来建立起商品的信息知识库,建立商品之间的相关度。
比如,汽车之家的所有的车型,包括了汽车的各种性能参数;电商网站中的女装也包括了各种规格。
在内容的推荐过程中,只需要利用用户当时的上下文情况:例如用户正在看一个20万左右的大众轿车,系统就会根据这辆车的性能参数,来找到另外几辆与这辆车相似的车来推荐给用户。
一般来说,建立这样的数据库需要专业人士、编辑等通过手动完成,有一定的工作量,但对于冷启动阶段的产品来说,是一个相对有效的方法。
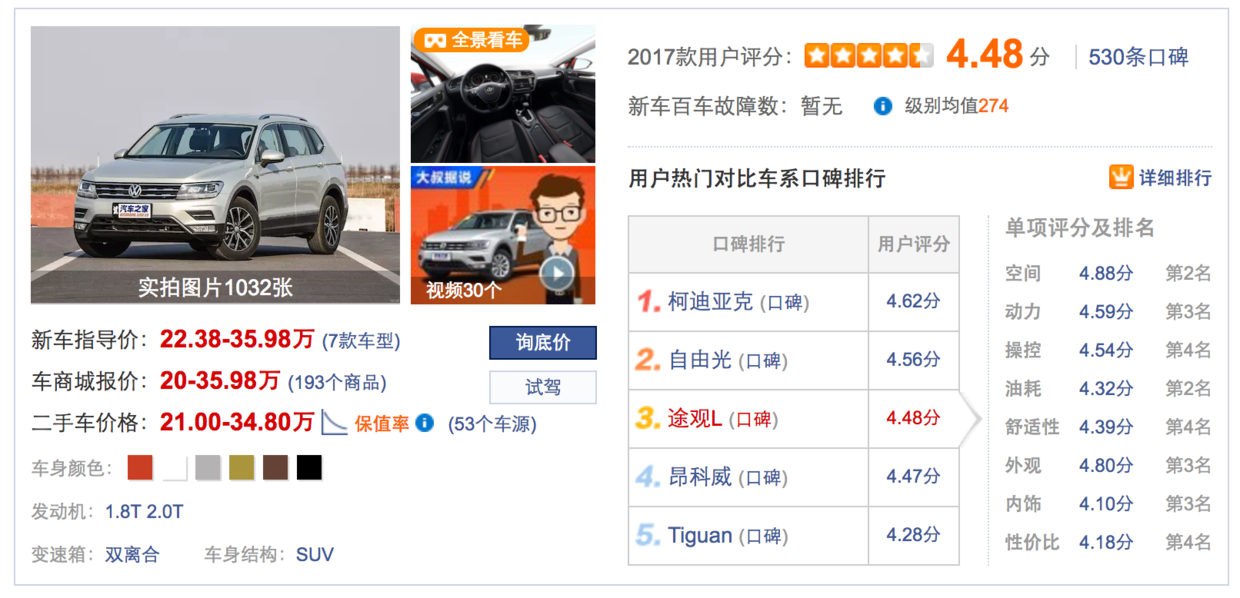
汽车之家网站在用户查看一辆车的同时推荐与其相似的车
另外一种情况是纯文本的内容没有明确的参数特征,在这种情况下,需要通过文本分析技术来自动提取文本的关键词(通过自然语言技术的进行分词),通过数据挖掘来找到文本与文本之间的联系和相似性。
热度算法

左:微博 右:今日头条
另外,由于各种社会热点话题普遍是人们关注较高的,以及由于在产品发展初期,没有收集到大量用户数据的情况下,“热度算法”也是一种惯常使用的方式。
“热度算法“即将热点的内容优先推荐给用户。
这里值得注意的是,热点不会永远是热点,而是具有时效性的。
所以发布初期用热度算法实现冷启动,积累了一定量级以后,才能逐渐开展个性化推荐算法。
而热度算法在使用时也需要考虑到如何避免马太效应:毋庸置疑的是,在滚雪球的效应之下,互联网民的消费&观点&行为会趋同,就像前一阵《战狼2》的热映一样,史无前例的票房成绩完全取决于铺天盖地式的宣传,而群体将会成为乌合之众。
每个有推荐功能的产品都会遇到冷启动(cold start)的问题,也是很多创业公司遇到的较为棘手的问题。
在早期团队资金有限的情况下,如何更好地提升用户体验?
如果给用户的推荐千篇一律、没有亮点,会使得用户在一开始就对产品失去了兴趣,放弃使用。所以冷启动的问题需要上线新产品认真地对待和研究。
在产品刚刚上线,新用户到来的时候,如果没有他在应用上的行为数据,也无法预测其兴趣。另外,当新商品上架也会遇到冷启动的问题,没有收集到任何一个用户对其浏览,点击或者购买的行为,也无从判断将商品如何进行推荐。
所以在冷启动的时候要同时考虑用户的冷启动和物品的冷启动。
我总结了并延伸了项亮在《推荐系统实践》中的一些方法,可以参考:
联系我们
一站式管家服务、我们坚持24小时接受呼叫,感谢您对我们的信任!

来电咨询
400-661-2208

QQ咨询
920796682

微信咨询
13764908986

旺旺咨询
caomingcsdn